AtomS3でフラッシュ暗算する
8MB のFLASHでDeep Learningは動くのか!? 柏井
はじめに
最近の私たちの身近な環境でも、AI技術によって革新的な発展を遂げています。
ChatGPTやGeminiを使用して求めている情報を調べたり、自動運転で運転手の負担を減らしたり、このような技術はAIが使用されています。
そういったAIで生活を便利にしたりより快適にしたりするためには、スマートフォンやスピーカーなどの身近なデバイスにAIを搭載していく必要があります。
しかし、これらのデバイスには限られたリソース(CPUやメモリ)上で動かさないといけない制約があります。
この限られたリソース上でより高性能なAIを実現するかがこれからのAI研究開発において重要な課題となっています。
そうした開発の中で、"AI × エッジデバイス" の可能性をより広げていきたいと思っております。
本コラムでは、ESP32のデバイスの "AtomS3" でディープラーニングを動かします。
AtomS3は製品サイズが 24*24mm と非常に小さいデバイスで制約が厳しいデバイスに対してAIを搭載できるか挑戦していきます。
本コラムを読んでいる人には、"これでディープラーニングを動かせるの!?"と、驚きや面白さを感じ、楽しんでいただきたいです。

今回すること
今回はAtomS3を活用して、「AtomS3とカメラを接続して、リアルタイムフラッシュ暗算」をしたいと思います。
AIのモデルはMNISTデータセットを学習した3層ニューラルネットワークモデルを使用します。
ディスプレイに写したフラッシュ暗算動画をカメラでキャプチャしたものを入力に使用します。
カメラは "Unit-CAM" を使用します。AtomS3にGrove - 4ピンケーブルをUnit-CAMと接続して、デバイス間通信はUARTを使用します。

Unit-CAMとは
"Unit-CAM" とは、ESP32-WROOM-32E MCUとOV2640 2メガピクセル(MP)イメージセンサを搭載したWi-Fiカメラです。
画像データの取得、編集、インターフェースなどの機能を備えており、取得する画素、画質(JPEGのみ)や形式(PNG、JPEG、Grayscaleなど)を設定できます。
Wi-Fiが搭載されているので、ワイヤレスカメラに使用するなどの用途があります。
今回はUnit-CAMのコードも変更していくため、本コラムのコードを書き込む場合にはFlash Downloader Kit(別売)が必要になります。
動作環境 について
システム構成としては、以下の通りです。
- 推論: AtomS3
- 開発環境: PlatformIO
- キャプチャ: Unit-CAM
- 開発環境: ArduinoIDE
- 通信: UART
次に推論・キャプチャ処理を実行する環境についてです。デバイスの詳細は以下の通りです。

- AtomS3
- MCU: ESP32-S3FN8
- Flash: 8MB
- MCU: dual-core
- Wi-Fi: 2.4G
- BLE: 5.0 combo
- DCDC: SY8089
- IMU: MPU6886
- 解像度: 128(H)RGB×128(V)
- 対応電圧: 5V
- 出力電圧: 3.3V
- Unit-CAM
- Flash: 4MB
- UART: 115200bps 8N1
- カメラセンサ: OV2640
- 最大解像度: 2MegaPixel
- 送信レート: 12fps
- 視野角: 66.5°
- サポート出力フォーマット
- YUV(422/420)/YCbCr422
- 8-bit compressed data
- RGB565/555
- 8-/10-bit
- Raw RGB data

Unit-CAM で画像を取得してみる
まずは、Unit-CAMで画像を取得します。
画像取得はesp_cameraライブラリの "esp_camera_fb_get()" 関数を呼び出すことで、バッファにスタックされている画像データを取得してきます。
下記のように実装することで画像の取得ができます。
※コードはファイル名をクリックしていただくと閲覧できます。
▶unit-cam.cpp
#include "esp_camera.h"
// PIN MAP
#define CAM_PIN_PWDN -1
#define CAM_PIN_RESET 15
#define CAM_PIN_XCLK 27
#define CAM_PIN_SIOD 25
#define CAM_PIN_SIOC 23
#define CAM_PIN_D7 19
#define CAM_PIN_D6 36
#define CAM_PIN_D5 18
#define CAM_PIN_D4 39
#define CAM_PIN_D3 5
#define CAM_PIN_D2 34
#define CAM_PIN_D1 35
#define CAM_PIN_D0 32
#define CAM_PIN_VSYNC 22
#define CAM_PIN_HREF 26
#define CAM_PIN_PCLK 21
static camera_config_t config = {
.pin_pwdn = CAM_PIN_PWDN,
.pin_reset = CAM_PIN_RESET,
.pin_xclk = CAM_PIN_XCLK,
.pin_sccb_sda = CAM_PIN_SIOD,
.pin_sccb_scl = CAM_PIN_SIOC,
.pin_d7 = CAM_PIN_D7,
.pin_d6 = CAM_PIN_D6,
.pin_d5 = CAM_PIN_D5,
.pin_d4 = CAM_PIN_D4,
.pin_d3 = CAM_PIN_D3,
.pin_d2 = CAM_PIN_D2,
.pin_d1 = CAM_PIN_D1,
.pin_d0 = CAM_PIN_D0,
.pin_vsync = CAM_PIN_VSYNC,
.pin_href = CAM_PIN_HREF,
.pin_pclk = CAM_PIN_PCLK,
.xclk_freq_hz = 20000000,
.ledc_timer = LEDC_TIMER_0,
.ledc_channel = LEDC_CHANNEL_0,
.pixel_format = PIXFORMAT_JPEG,
.frame_size = FRAMESIZE_96X96,
.jpeg_quality = 16, // 数値が大きいほど圧縮する
.fb_count = 3, // CAMERA_GRAB_LATEST設定時は2以上必要
.fb_location = CAMERA_FB_IN_DRAM, // Unit CAMの場合はPSRAMがないのでDRAMを指定
.grab_mode = CAMERA_GRAB_LATEST
};
void setup() {
// Serial0 はUSBデバッグ用
Serial.begin(115200);
// Serial1 は自由に使えるため、UARTとして使用
Serial1.begin(115200, SERIAL_8N1, 17, 16);
if(CAM_PIN_PWDN != -1){
pinMode(CAM_PIN_PWDN, OUTPUT);
digitalWrite(CAM_PIN_PWDN, LOW);
}
//initialize the camera
esp_err_t err = esp_camera_init(&config);
if (err != ESP_OK) {
ESP_LOGE(TAG, "Camera Init Failed");
return;
}
sensor_t *s = esp_camera_sensor_get();
// 画像反転
s->set_vflip(s, 1);
s->set_hmirror(s, 1);
}
void loop() {
// 画像取得
camera_fb_t *fb = esp_camera_fb_get();
if (fb) {
// 画像送信
// UDPのため開始時の文字を設定する(Bee)
Serial1.print("Bee");
Serial1.write((byte *)&(fb->len), 4); // サーバーのためにバッファサイズを送信しておく
Serial1.write((const uint8_t *)fb->buf, fb->len);
}
// バッファの解放
esp_camera_fb_return(fb);
}
上記コードで画像が取得できているはず。。。
ですので、可視化して確認できるように準備します。"Serial1"(GROVE/UART通信)で送信した画像をAtomS3で取得して表示してみます。
Unit-CAMでは"Bee" → Data size → Image data の順に送信し、受信側は順にシリアルデータを読み込んで処理します。
AtomS3では読み込んだデータの先頭の"Bee"を見つけたら、その後データサイズ、画像データを読み出します。
▶atoms3.cpp
#include <M5AtomS3.h>
TaskHandle_t thp[3];//マルチスレッドのタスクハンドル格納用
static LGFX_Sprite sprite_img(&M5.Display);
void serve_image(void *args){
BaseType_t xStatus;
// Display Grayscale Image
auto bpp = (lgfx::color_depth_t) lgfx::color_depth_t::grayscale_8bit;
auto forecolor = 0xFFFF;
auto backcolor = 0x0000;
while(1) {
// データ区切り用文字列(DATA)
if (Serial1.available() > 4){
if (Serial1.read() == 'B') {
if (Serial1.read() == 'e') {
if (Serial1.read() == 'e') {
// サイズ取得
Serial1.readBytes((uint8_t *)src_buf, 4);
uint8_t *int_buf = (uint8_t *)src_buf;
data_size = int_buf[0] | int_buf[1] << 8 | int_buf[2] << 16 | int_buf[3] << 24; // byte[4] -> size_t(int)
// データ取得
Serial1.readBytes((uint8_t *)src_buf, data_size);
printf("D size: %d\n", data_size);
sprite_img.drawJpg((const uint8_t*) src_buf, 0, 0, IMAGE_WIDTH, IMAGE_HEIGHT, 0, 0, 1.0f, 1.0f);
sprite_img.pushSprite(0, 0);
}
}
}
}
vTaskDelay(10);
}
delay(10);
}
void setup() {
auto cfg = M5.config();
M5.begin(cfg);
M5.Lcd.init(); // 初期化
// USBシリアル通信(確認用)
Serial.begin(115200);
// GROVEのシリアル通信(UART)
Serial1.begin(115200, SERIAL_8N1, 1, 2); // PORT-A(Red)(GPIO21, GPIO22)
M5.Lcd.setTextSize(1);
// LCD Settings
M5.Lcd.setBrightness(64);
M5.Lcd.setColorDepth(24);
sprite_img.setColorDepth(24);
sprite_img.createSprite(96, 96);
sprite_img.setSwapBytes(true);
xTaskCreatePinnedToCore(serve_image, "serve_image", 2048, NULL, 2,(TaskHandle_t *) &thp[0], PRO_CPU_NUM);
delay(100);
}
void loop() {
M5.update();
delay(1);
}

GROVE経由で受信した画像がAtomS3に表示されました。取得した画像はスプライトでLCDに描画しています。
AtomS3の画面の解像度は 128x128 であるものの綺麗に表示できています。
これで画像の送受信、描画を確認できました。
MNISTの準備_取得イメージについて
フラッシュ暗算をするためには、より高速に推論処理をしなければ数字を見逃してしまう可能性があります。
一瞬映る数字を捉えるためには、最低でも数字の切り替わりごとに1フレームは必要となります。
MNISTの入力として、JPEGのままでは処理が難しいため(JPEGで学習されているモデルもありますが。)、処理が簡単なRAWデータ形式にします。
ボーレートが115,200Hz(bps)で送信できるフレーム数はRAWデータ画像(3チャネル)のカメラ取得時の最小解像度(96x96)であった場合、
FPS(frames per second) = bps(bits/s) / 1frame(bits/frame) と計算できるので、理論値を算出すると、
115,200 / (96 x 96 x 8 x 3) = 115,200 / 221,184 = 0.52 FPS となります。(遅すぎる。。。)
これでは話にならないので、グレースケールへの変換をします。
8bitグレースケールの理論値は単純に3チャネル→1チャネルになるので、1.5FPS (上記の3倍) となります。
以下はUnit-CAMのコードでグレースケールによるキャプチャを実施します。
▶unit-cam.cpp
#include "esp_camera.h"
// PIN MAP
#define CAM_PIN_PWDN -1
#define CAM_PIN_RESET 15
#define CAM_PIN_XCLK 27
#define CAM_PIN_SIOD 25
#define CAM_PIN_SIOC 23
#define CAM_PIN_D7 19
#define CAM_PIN_D6 36
#define CAM_PIN_D5 18
#define CAM_PIN_D4 39
#define CAM_PIN_D3 5
#define CAM_PIN_D2 34
#define CAM_PIN_D1 35
#define CAM_PIN_D0 32
#define CAM_PIN_VSYNC 22
#define CAM_PIN_HREF 26
#define CAM_PIN_PCLK 21
static camera_config_t config = {
.pin_pwdn = CAM_PIN_PWDN,
.pin_reset = CAM_PIN_RESET,
.pin_xclk = CAM_PIN_XCLK,
.pin_sccb_sda = CAM_PIN_SIOD,
.pin_sccb_scl = CAM_PIN_SIOC,
.pin_d7 = CAM_PIN_D7,
.pin_d6 = CAM_PIN_D6,
.pin_d5 = CAM_PIN_D5,
.pin_d4 = CAM_PIN_D4,
.pin_d3 = CAM_PIN_D3,
.pin_d2 = CAM_PIN_D2,
.pin_d1 = CAM_PIN_D1,
.pin_d0 = CAM_PIN_D0,
.pin_vsync = CAM_PIN_VSYNC,
.pin_href = CAM_PIN_HREF,
.pin_pclk = CAM_PIN_PCLK,
.xclk_freq_hz = 20000000,
.ledc_timer = LEDC_TIMER_0,
.ledc_channel = LEDC_CHANNEL_0,
.pixel_format = PIXFORMAT_GRAYSCALE,
.frame_size = FRAMESIZE_96X96, // 画像サイズを縮小
.fb_count = 3, // CAMERA_GRAB_LATEST設定時は2以上必要
.fb_location = CAMERA_FB_IN_DRAM, // Unit-CAMの場合はPSRAMがないのでDRAMを指定
.grab_mode = CAMERA_GRAB_LATEST
};
void setup() {
// Serial0 はUSBデバッグ用
Serial.begin(115200);
// Serial1 は自由に使えるため、UARTとして使用
Serial1.begin(115200, SERIAL_8N1, 17, 16);
if(CAM_PIN_PWDN != -1){
pinMode(CAM_PIN_PWDN, OUTPUT);
digitalWrite(CAM_PIN_PWDN, LOW);
}
//initialize the camera
esp_err_t err = esp_camera_init(&config);
if (err != ESP_OK) {
ESP_LOGE(TAG, "Camera Init Failed");
return;
}
sensor_t *s = esp_camera_sensor_get();
// 画像反転
s->set_vflip(s, 1);
s->set_hmirror(s, 1);
}
void loop() {
// 画像取得
camera_fb_t *fb = esp_camera_fb_get();
if (fb) {
// 画像送信
// UDPのため開始時の文字を設定する(Bee)
Serial1.print("Bee");
Serial1.write((byte *)&(fb->len), 4); // サーバーのためにバッファサイズを送信しておく
Serial1.write((const uint8_t *)fb->buf, fb->len);
// バッファの解放
esp_camera_fb_return(fb);
}
}
続いて、その取得した画像をそのままAtomS3に表示してみます。
グレースケール画像をそのままLCDに表示する関数へと変更します。
この時のグレースケール画像の受信側でのFPSを計測します。
▶atoms3.cpp
#include <M5AtomS3.h>
#define IMAGE_WIDTH 96
#define IMAGE_HEIGHT 96
TaskHandle_t thp[3];//マルチスレッドのタスクハンドル格納用
static LGFX_Sprite sprite_img(&M5.Display);
uint8_t src_buf[IMAGE_WIDTH*IMAGE_HEIGHT * 4];
size_t data_size;
// 総フレーム数
uint32_t cnt = 0;
// 取得開始タイムスタンプ用
float start = 0;
// 現タイムスタンプ用
float now = 0;
void serve_image(void *args){
BaseType_t xStatus;
// Display Grayscale Image
auto bpp = (lgfx::color_depth_t) lgfx::color_depth_t::grayscale_8bit;
int16_t forecolor = 0xFFFF;
int16_t backcolor = 0x0000;
start = millis();
while(1) {
// データ区切り用文字列(DATA)
if (Serial1.available() > 4){
if (Serial1.read() == 'B') {
if (Serial1.read() == 'e') {
if (Serial1.read() == 'e') {
// サイズ取得
Serial1.readBytes((uint8_t *)src_buf, 4);
uint8_t *int_buf = (uint8_t *)src_buf;
data_size = int_buf[0] | int_buf[1] << 8 | int_buf[2] << 16 | int_buf[3] << 24; // byte[4] -> size_t(int)
// データ取得
Serial1.readBytes((uint8_t *)src_buf, data_size);
cnt++;
now = millis();
printf("Current FPS: %f\n", cnt / ((now - start) / 1000));
// pushGrayscaleImage を使用してそのまま取得したデータを表示する
sprite_img.pushGrayscaleImage(0, 0, IMAGE_WIDTH, IMAGE_HEIGHT, (const uint8_t *) src_buf, lgfx::v1::color_depth_t::grayscale_8bit, forecolor, backcolor);
// sprite_img.drawJpg((const uint8_t*) src_buf, data_size, 0, 0, IMAGE_WIDTH, IMAGE_HEIGHT, 0, 0, 1.0f, 1.0f);
sprite_img.pushSprite(0, 0);
}
}
}
}
vTaskDelay(10);
}
delay(10);
}
void setup() {
auto cfg = M5.config();
M5.begin(cfg);
M5.Lcd.init(); // 初期化
// USBシリアル通信(確認用)
Serial.begin(115200);
// GROVEのシリアル通信(UART)
Serial1.begin(115200, SERIAL_8N1, 1, 2); // PORT-A(Red)(GPIO21, GPIO22)
M5.Lcd.setTextSize(1);
// LCD Settings
M5.Lcd.setBrightness(64);
M5.Lcd.setColorDepth(24);
sprite_img.setColorDepth(24);
sprite_img.createSprite(160, 160);
sprite_img.setSwapBytes(true);
xTaskCreatePinnedToCore(serve_image, "serve_image", 4096, NULL, 2,(TaskHandle_t *) &thp[0], PRO_CPU_NUM);
delay(100);
}
void loop() {
M5.update();
delay(1);
}
画像の表示はM5ライブラリをそのまま使用するだけなので、簡単に表示することができます。
OSSのありがたみを感じる瞬間ですね。
画像を表示した結果はどうでしょうか。

植物や壁面に飾られたレコードのジャケット画が映るように取得しているのですが、しっかりとグレースケールになっていました。
この状態のFPSはどうでしょうか。
Current FPS: 0.973710
Current FPS: 1.093494
Current FPS: 1.139818
Current FPS: 1.164822
Current FPS: 1.180359
Current FPS: 1.190949
Current FPS: 1.198630
Current FPS: 1.206273
ちょっと、遅すぎます。。。
理論値自体は1.5FPS程度のはずですが、受け取り、描画処理が発生してしまうためか、1.0FPS程度しか出ません。
FPSはUARTのボーレートに依存してしまうので、画像送信データを圧縮等しないとこれ以上の速度が望めません。
画像の2値データ変換
次は、画像を2値データへと圧縮してみます。
送信側のUnit-CAM にて取得したグレースケールデータをある閾値で線引きして2値変換します。
2値画像への変換イメージは、下記の図のイメージです。
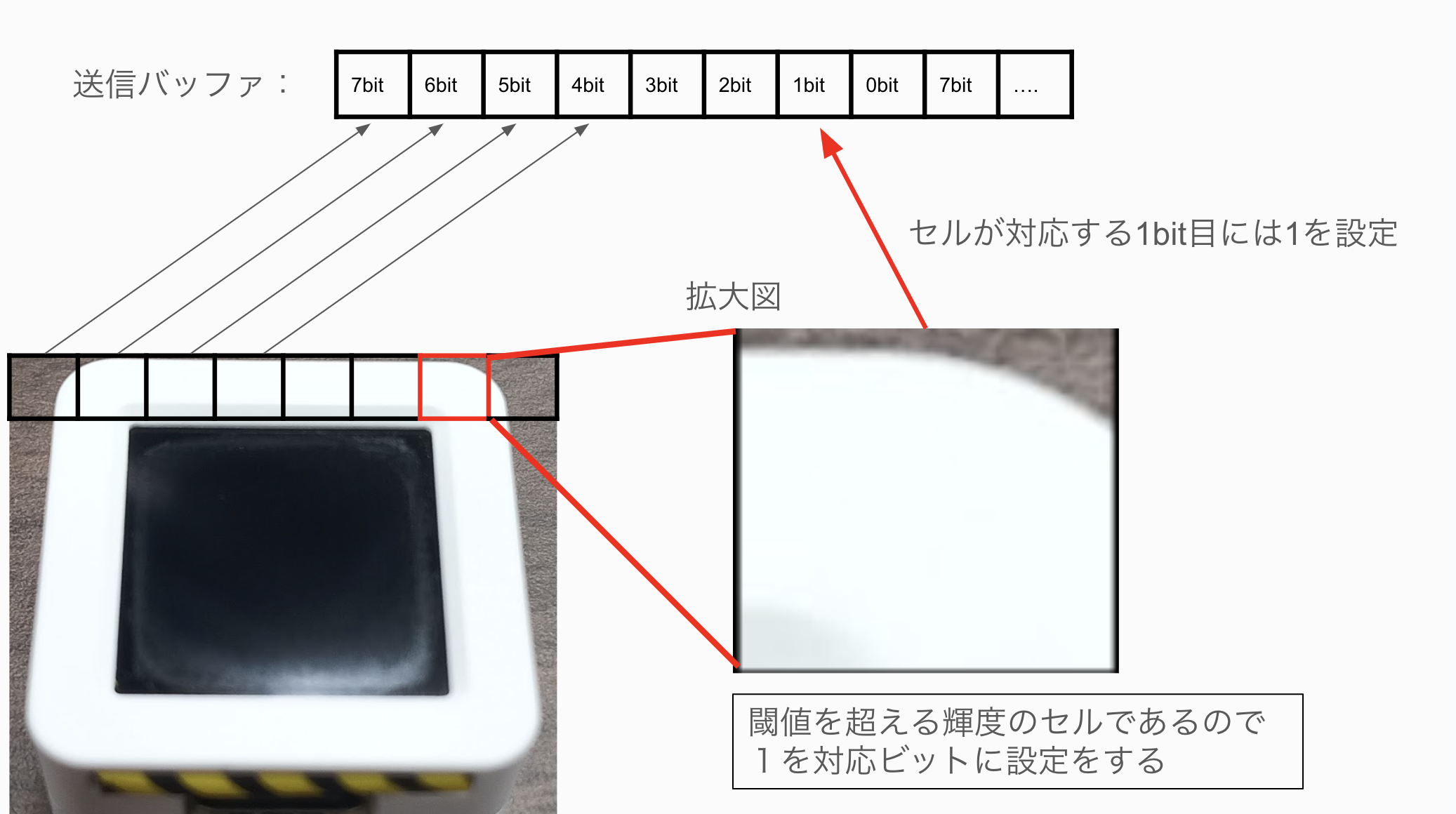
AtomS3の表示系は7bit目から0bit目に順に描画するので、高位ビットから下位ビットへと対応するピクセルの値を変換した
2値データをバッファへ格納する処理をUnit-CAMで実施してからAtomS3に画像を送信します。
下記コードでは、閾値を設けており、その閾値を超える色情報(明るさ)であればそのピクセルを1に、
閾値以下の数値のデータは0に設定しています。
環境に応じて、THREASHOLDの値は変更しないと真っ黒な画像になる可能性はあります。
▶unit-cam.cpp
#include "esp_camera.h"
// PIN MAP
#define CAM_PIN_PWDN -1
#define CAM_PIN_RESET 15
#define CAM_PIN_XCLK 27
#define CAM_PIN_SIOD 25
#define CAM_PIN_SIOC 23
#define CAM_PIN_D7 19
#define CAM_PIN_D6 36
#define CAM_PIN_D5 18
#define CAM_PIN_D4 39
#define CAM_PIN_D3 5
#define CAM_PIN_D2 34
#define CAM_PIN_D1 35
#define CAM_PIN_D0 32
#define CAM_PIN_VSYNC 22
#define CAM_PIN_HREF 26
#define CAM_PIN_PCLK 21
struct frame_info_t {
uint8_t *buf;
uint16_t len;
};
#define THREASHOLD 200
static camera_config_t config = {
.pin_pwdn = CAM_PIN_PWDN,
.pin_reset = CAM_PIN_RESET,
.pin_xclk = CAM_PIN_XCLK,
.pin_sccb_sda = CAM_PIN_SIOD,
.pin_sccb_scl = CAM_PIN_SIOC,
.pin_d7 = CAM_PIN_D7,
.pin_d6 = CAM_PIN_D6,
.pin_d5 = CAM_PIN_D5,
.pin_d4 = CAM_PIN_D4,
.pin_d3 = CAM_PIN_D3,
.pin_d2 = CAM_PIN_D2,
.pin_d1 = CAM_PIN_D1,
.pin_d0 = CAM_PIN_D0,
.pin_vsync = CAM_PIN_VSYNC,
.pin_href = CAM_PIN_HREF,
.pin_pclk = CAM_PIN_PCLK,
.xclk_freq_hz = 20000000,
.ledc_timer = LEDC_TIMER_0,
.ledc_channel = LEDC_CHANNEL_0,
.pixel_format = PIXFORMAT_GRAYSCALE,
.frame_size = FRAMESIZE_96X96,
.fb_count = 3, // CAMERA_GRAB_LATEST設定時は2以上必要
.fb_location = CAMERA_FB_IN_DRAM, // Unit CAMの場合はPSRAMがないのでDRAMを指定
.grab_mode = CAMERA_GRAB_LATEST
};
void setup() {
// Serial0 はUSBデバッグ用
Serial.begin(115200);
// Serial1 は自由に使えるため、UARTとして使用
Serial1.begin(115200, SERIAL_8N1, 17, 16);
if(CAM_PIN_PWDN != -1){
pinMode(CAM_PIN_PWDN, OUTPUT);
digitalWrite(CAM_PIN_PWDN, LOW);
}
//initialize the camera
esp_err_t err = esp_camera_init(&config);
if (err != ESP_OK) {
ESP_LOGE(TAG, "Camera Init Failed");
return;
}
sensor_t *s = esp_camera_sensor_get();
// 画像反転
s->set_vflip(s, 1);
s->set_hmirror(s, 1);
}
// 取得ピクセルを1byteに8pixelをセット
void convert_frame2bit(camera_fb_t *fb, frame_info_t *output){
// 取得したグレースケールのバッファサイズを8で割る
output->len = fb->len / 8;
output->buf = new uint8_t[output->len];
for (int i = 0; i < output->len; i++){
uint8_t color = 0x00;
// 7bit目から順に閾値を越えれば1をそうでなければ0をセット
for(int8_t n_bit=0; n_bit < 8; n_bit++){
if(fb->buf[8*i + n_bit] > THREASHOLD) color |= (0x01 << (7 - n_bit));
}
output->buf[i] = color;
}
}
void loop() {
// 画像取得
camera_fb_t *fb = esp_camera_fb_get();
if (fb) {
frame_info_t frame;
convert_frame2bit(fb, &frame);
// 画像送信
// UDPのため開始時の文字を設定する(Bee)
Serial1.print("Bee");
Serial1.write((byte *)&(frame.len), 4); // サーバーのためにバッファサイズを送信しておく
Serial1.write((const uint8_t *)frame.buf, frame.len);
// バッファの解放
esp_camera_fb_return(fb);
delete frame.buf;
}
}
AtomS3の対応としては"pushGrayscaleImage"メソッドの引数の"grayscale_8bit" → "grayscale_1bit"にするだけです。
forecolorとbackcolorに指定されている値は、1が入ったピクセルを"forecolor"、0が入ったピクセルを"backcolor"で描画してくれます。
描画された画像は以下の通りとなりました。

プログラムコードをカメラで取得したものですが、表示している画像からも文字が並んでいるように感じ取れます。
2値データでも画像から何が写っているのかが分かるレベルになりました。
そのFPSを計測してみましょう。
Current FPS: 9.935251
Current FPS: 9.935386
Current FPS: 9.935327
Current FPS: 9.935250
Current FPS: 9.935385
Current FPS: 9.935308
Current FPS: 9.935249
Current FPS: 9.935384
10FPS程度が安定して出ています。
これでフラッシュ暗算するために、必要十分なFPSが出るようになりました。
MNIST学習したNNモデルの作成
そもそもMNISTとは、MNISTデータベースの略称で手描き数字文字画像のデータベース(データセット)のことで、このMNISTデータセットを使用して
数字文字を認識してクラス(0-9)分類させる深層学習モデルを学習します。
今回は3層ニューラルネットワーク(NN)と活性化関数はReLUを使用します。
2値画像を入力して推論させるイメージですので、2値画像に変換したMNISTデータセットを学習させます。
今回、言語はPythonを使用し、学習フレームワークはPyTorchにします。
▶mnist.py
from torch.utils.data import Dataset
import torch
import torchvision
import torchvision.transforms as transforms
import torch.optim as optim
import matplotlib
matplotlib.use('tkagg')
import matplotlib.pyplot as plt
EPOCHS = 10
THREASHOLD = 150
INPUT_FEATURES = 28 * 28
HIDDEN = 48
OUTPUT_FEATURES = 10
BATCH_SIZE = 20
class Net(torch.nn.Module):
def __init__(self, INPUT_FEATURES, HIDDEN, OUTPUT_FEATURES):
super().__init__()
HIDDEN_MID = HIDDEN * 2
self.fc1 = torch.nn.Linear(INPUT_FEATURES, HIDDEN, dtype=torch.float32)
self.fc2 = torch.nn.Linear(HIDDEN, HIDDEN_MID, dtype=torch.float32)
self.fc3 = torch.nn.Linear(HIDDEN_MID, OUTPUT_FEATURES, dtype=torch.float32)
self.softmax = torch.nn.Softmax(dim=1)
def forward(self, x):
func = torch.nn.functional.relu
x = self.fc1(x)
x = func(x)
x = self.fc2(x)
x = func(x)
x = self.fc3(x)
return x
class BinaryMNIST(Dataset):
def __init__(self, dataset):
self.images , self.labels = dataset.data, dataset.targets
def __len__(self):
return len(self.labels)
def __getitem__(self, idx):
image, label = self.images[idx], self.labels[idx]
image = image.float()
image[image < THREASHOLD] = -1.0
image[image >= THREASHOLD] = 1.0
image = image.to(torch.float)
# do the necessary transforms ...
return image, label
def outputModel(net):
param_dict = dict(net.state_dict())
param_weight = ""
param_bias = ""
param_input = "const int "
layer_names = ["fc1", "fc2", "fc3"]
layer_names = [f"{name}.weight" for name in layer_names]
bias_names = ["fc1", "fc2", "fc3"]
bias_names = [f"{name}.bias" for name in bias_names]
def createLayer(num_, input, output):
ret_str = ""
num_in = f"W{num_+1}"
layer = list(param_dict[layer_names[num_]].T)
ret_str += f"const float {num_in}[N{num_}][N{num_+1}] = {{\n"
for index in range(input):
ret_str += "{"
for param in layer[index]:
ret_str += f"{round(float(param), 10)}, "
ret_str += "},\n"
ret_str += "};\n"
return ret_str
def createBias(num_, input, output):
ret_str = ""
num_in = f"b{num_+1}"
biases = list(param_dict[bias_names[num_]])
ret_str += f"const float {num_in}[N{num_+1}] = {{"
for bias in biases:
ret_str += f"{round(float(bias), 10)}, "
ret_str += "};\n"
return ret_str
for num in range(3):
# hidden layer
func = getattr(net, f"fc{num+1}")
in_f = func.in_features
out_f = func.out_features
param_weight += createLayer(num, in_f, out_f)
param_bias += createBias(num, in_f, out_f)
param_input += f"N{num} = {in_f}, "
param_input += f"N{num+1} = {out_f};\n"
param_str = param_input + param_weight + param_bias
with open("./param_config.h", mode="w") as file:
file.write(param_str)
file.flush()
file.close()
def main():
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True)
train_dataset = BinaryMNIST(trainset)
trainloader = torch.utils.data.DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=True, download=True)
test_dataset = BinaryMNIST(testset)
testloader = torch.utils.data.DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
net = Net(INPUT_FEATURES, HIDDEN, OUTPUT_FEATURES)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(1, EPOCHS + 1):
running_loss = 0.0
for count, item in enumerate(trainloader, 1):
inputs, labels = item
inputs = inputs.reshape(-1, 28 * 28)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if count % 500 == 0:
print(f'#{epoch}, data: {count * 20}, running_loss: {running_loss / 500:1.3f}')
running_loss = 0.0
print('Finished')
_, predicted = torch.max(outputs, 1)
print(predicted)
print(labels)
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
inputs, labels = data
inputs = inputs.reshape(-1, 28 * 28)
outputs = net(inputs)
_, predicted = torch.max(outputs, 1)
total += len(outputs)
correct += (predicted == labels).sum().item()
print(f'correct: {correct}, accuracy: {correct} / {total} = {correct / total}')
outputModel(net)
if __name__ == "__main__":
main()
上記を実行するには下記の通りに実行してください。
# 仮想環境を用意する場合は実行してください。
python3.10 -m venv venv
source venv/bin/activate
# 下記、初回に一度だけ実行
python -m pip install matplotlib==3.9.2 torch==2.4.0 torchvision==0.19.0
python mnist.py
# 出力ファイルを確認
ls
data mnist.py param_config.h venv
実行結果は、"param_config.h" ファイルが出力されるので、そのファイルを以降のAtomS3用推論コードで使用します。
AtomS3で数字文字認識させる
実際に学習したモデルを使用して、推論してみます。
推論するためのコードでは、AtomS3の負荷の分散のために描画、推論に分けて並列処理させます。
推論結果を画面に出力して視認できるようにしています。下記コードはAtomS3用です。
▶atoms3.cpp
#include <M5AtomS3.h>
#include "param_config.h"
#define IMAGE_WIDTH 96
#define IMAGE_HEIGHT 96
#define MNIST_WIDTH 28
#define MNIST_HEIGHT 28
#define PREDICT_THREASHOLD 6.0
#define PRED_X_WIDTH 32
#define PRED_X_HEIGHT 48
struct MAX {
float_t pred;
float_t max_prob;
int8_t label;
};
const int Num = 10;
float_t z1[N1], z2[N2], y[N3];
TaskHandle_t thp[3];//マルチスレッドのタスクハンドル格納用
static LGFX_Sprite sprite_img(&M5.Display);
static LGFX_Sprite sprite_pred(&M5.Display);
uint8_t src_buf[IMAGE_WIDTH*IMAGE_HEIGHT / 2];
uint8_t tgt_buf[IMAGE_WIDTH*IMAGE_HEIGHT / 2];
// MNISTの入力バッファ
uint8_t gray8[IMAGE_WIDTH*IMAGE_HEIGHT];
float_t gray_f[MNIST_WIDTH*MNIST_HEIGHT];
SemaphoreHandle_t xMutex = NULL;
SemaphoreHandle_t xImgMutex = NULL;
// 現在フレームをインクリメントし、カウント
uint8_t frame_num = 0;
// 推論をするフレームの↑のフレーム番号を代入してから推論開始する
// 同フレーム番号だった場合には推論しない
uint8_t predicted_num = 0;
size_t data_size;
uint32_t cnt = 0;
float start = 0;
float now = 0;
void Transmission(const float* input, float *output, int numInput, int numOutput, const float* W, const float* b, bool act) {
for (int i = 0; i < numOutput; ++i) {
for (int j = 0; j < numInput; ++j) {
// y = W * x + b
output[i] += W[j * numOutput + i] * input[j];
}
output[i] += b[i];
// ReLU
if (act) output[i] = output[i] < 0 ? 0 : output[i];
}
}
struct MAX Softmax(const float_t* input, float_t* output){
float_t exp_arr[Num];
float_t pred_sum;
for (int i=0; i < Num; i++) {
printf("[%d] Pred: %f\n", i, input[i]);
exp_arr[i] = exp(input[i]);
pred_sum += exp_arr[i];
}
for (int i=0; i < Num; i++) {
output[i] = exp_arr[i] / pred_sum;
}
struct MAX max = {-1.0, -1.0, -1,};
for (int i=0; i < Num; i++) {
if (max.max_prob < output[i]) {
max.pred = input[i];
max.max_prob = output[i];
max.label = i;
}
}
return max;
}
void get_8bit_array(const uint8_t *input, uint8_t *output, uint16_t size){
for(int i=0; i < size / 8; i++){
for(int nbit=0; nbit < 8; nbit++){
if((uint8_t)(input[i] && (0x01 << 7 - nbit)) > 0){
output[8*i + nbit] = 1;
} else {
output[8*i + nbit] = 0;
}
}
}
}
void normalize_image(const uint8_t *input_buf){
int start = 0;
uint32_t frame_px_sum = 0;
int32_t diff = 0;
get_8bit_array(input_buf, gray8, IMAGE_WIDTH*IMAGE_HEIGHT);
for(int y = 0; y < MNIST_HEIGHT; y++) {
for(int x = 0; x < MNIST_WIDTH; x++) {
uint32_t row1 = IMAGE_WIDTH*(3*y+start);
uint32_t col1 = 3*x+start;
uint32_t row2 = IMAGE_WIDTH*(3*y+start+1);
uint32_t col2 = 3*x+start+1;
uint32_t row3 = IMAGE_WIDTH*(3*y+start+2);
uint32_t col3 = 3*x+start+2;
// 周囲9ビットを丸め込んで 28x28に変形
float_t row1_val = ( gray8[row1 + col1] + gray8[row2 + col1] + gray8[row3 + col1]
+ gray8[row1 + col2] + gray8[row2 + col2] + gray8[row3 + col2]
+ gray8[row1 + col3] + gray8[row2 + col3] + gray8[row3 + col3] ) / 9;
uint16_t index = (x + MNIST_WIDTH * y);
if (row1_val > 0.6) {
gray8[index] = 255;
if (gray_f[index] < 0) diff++;
gray_f[index] = 1.0;
} else {
gray8[index] = 0;
if (gray_f[index] > 0) diff++;
gray_f[index] = -1.0;
}
}
}
}
void serve_image(void *args){
BaseType_t xStatus;
// Display Grayscale Image
auto bpp = (lgfx::color_depth_t) lgfx::color_depth_t::grayscale_8bit;
int16_t forecolor = 0xFFFF;
int16_t backcolor = 0x0000;
start = millis();
while(1) {
// データ区切り用文字列(DATA)
if (Serial1.available() > 4){
if (Serial1.read() == 'B') {
if (Serial1.read() == 'e') {
if (Serial1.read() == 'e') {
// サイズ取得
Serial1.readBytes((uint8_t *)src_buf, 4);
uint8_t *int_buf = (uint8_t *)src_buf;
data_size = int_buf[0] | int_buf[1] << 8 | int_buf[2] << 16 | int_buf[3] << 24; // byte[4] -> size_t(int)
// 画像をバッファコピーする
if (xSemaphoreTake(xImgMutex, portMAX_DELAY) == pdTRUE) {
// データ取得
Serial1.readBytes((uint8_t *)src_buf, data_size);
printf("D size: %d\n", data_size);
xSemaphoreGive(xImgMutex);
}
cnt++;
now = millis();
printf("Current FPS: %f\n", cnt / ((now - start) / 1000));
frame_num++;
if (xSemaphoreTake(xMutex, portMAX_DELAY) == pdTRUE) {
sprite_img.pushGrayscaleImage(0, 0, IMAGE_WIDTH, IMAGE_HEIGHT, (const uint8_t*) src_buf, lgfx::v1::color_depth_t::grayscale_1bit, 0xFFFF, 0);
sprite_img.pushSprite(0, 0);
xSemaphoreGive(xMutex);
}
}
}
}
}
vTaskDelay(10);
}
delay(10);
}
void deep_copy(const uint8_t* src, uint8_t* tgt, int dsize) {
memcpy(tgt, src, sizeof(src[0])*dsize);
}
int16_t predict_num(float *buf){
for (int i = 0; i < N1; ++i) z1[i] = 0;
for (int i = 0; i < N2; ++i) z2[i] = 0;
for (int i = 0; i < N3; ++i) y[i] = 0;
Transmission(buf, z1, N0, N1, (const float*)W1, b1, true);
Transmission(z1, z2, N1, N2, (const float*)W2, b2, true);
Transmission(z2, y, N2, N3, (const float*)W3, b3, false);
int16_t p = 0; // p is inferenced numerals.
float_t result[10];
struct MAX max_pred = Softmax(y, result);
if (max_pred.pred > PREDICT_THREASHOLD) {
p = max_pred.label;
} else {
p = -1;
}
return p;
}
void pred_task(void* args) {
BaseType_t xStatus;
char output_str[50];
bool pred_flg = true;
int16_t pred_tmp = -1;
while(1) {
bool send_flg;
bool go_flg = true;
int8_t label = -1;
if (predicted_num != frame_num){
predicted_num = frame_num;
if (xSemaphoreTake(xImgMutex, portMAX_DELAY) == pdTRUE) {
deep_copy(src_buf, tgt_buf, data_size);
xSemaphoreGive(xImgMutex);
}
normalize_image(tgt_buf);
pred_tmp = predict_num(gray_f);
if (pred_tmp < 0){
continue;
}
label = pred_tmp;
if (xSemaphoreTake(xMutex, portMAX_DELAY) == pdTRUE) {
sprintf(output_str, "%d", label);
sprite_pred.setCursor(0, 0);
sprite_pred.print(output_str);
sprite_pred.pushSprite(IMAGE_WIDTH+3, 12);
xSemaphoreGive(xMutex);
}
}
vTaskDelay(10);
}
delay(10);
}
void setup() {
auto cfg = M5.config();
M5.begin(cfg);
M5.Lcd.init(); // 初期化
// USBシリアル通信(確認用)
Serial.begin(115200);
// GROVEのシリアル通信(UART)
Serial1.begin(115200, SERIAL_8N1, 1, 2); // PORT-A(Red)(GPIO21, GPIO22)
M5.Lcd.setTextSize(1);
// LCD Settings
M5.Lcd.setBrightness(64);
M5.Lcd.setColorDepth(24);
printf("M5 AtomS3 LCD finish initialize.\n");
sprite_img.setColorDepth(24);
sprite_img.createSprite(IMAGE_WIDTH, IMAGE_HEIGHT);
sprite_img.setSwapBytes(true);
printf("Sprite for image finish initialize.\n");
sprite_pred.setTextSize(3);
sprite_pred.setColorDepth(8);
sprite_pred.createSprite(PRED_X_WIDTH, PRED_X_HEIGHT);
printf("Sprite for prediction finish initialize.\n");
xMutex = xSemaphoreCreateMutex();
xImgMutex = xSemaphoreCreateMutex();
if( xMutex != NULL && xImgMutex != NULL){
xSemaphoreGive(xMutex);
xSemaphoreGive(xImgMutex);
// xTaskCreatePinnedToCore(serve_image, "serve_image", 4096, NULL, 25,(TaskHandle_t *) &thp[0], APP_CPU_NUM);
xTaskCreatePinnedToCore(serve_image, "serve_image", 2048, NULL, 2,(TaskHandle_t *) &thp[0], PRO_CPU_NUM);
xTaskCreatePinnedToCore(pred_task, "pred_task", 4096, NULL, 2,(TaskHandle_t *) &thp[2], APP_CPU_NUM);
} else {
while(1){
Serial.println("rtos mutex create error, stopped");
delay(1000);
}
}
delay(100);
}
void loop() {
M5.update();
delay(1);
}

動かしてみたところ、推論のブレが多少あることと認識しづらい数字文字があるように感じますが、
リソースの制約が強いマイコン上でも狙い通りの高FPSを維持した状態で推論できてそうです。
その認識しづらい課題の解決は、入力画像の見直しを実施して対策します。
学習画像と入力画像を近似させる
実際に学習する画像とカメラで取得して推論させる画像にギャップがあります。
そのため、そのギャップを取り除く必要があります。
学習時の入力データであるMNISTデータセットの前処理として2値画像変換をするのですが、その閾値を調整します。
閾値の値としてはUnit-CAMで取得する画像とより近しい手書き数字文字となるようにします。
Unit-CAMで取得した画像は数字が太めでくっきりとしているため、MNISTデータセットの変換する際の閾値を下げてあげることで、
線が太い手書き文字に変換できます。
同様にUnit-CAMでの2値画像変換時の閾値を変更する必要もあります。Unit-CAMでは2値画像で取得できる数字文字の線が太すぎるので、
今回はグレースケールのピクセル値が255の場合のみ"1"を設定し、それ以外を"0"になるようにしました。
それに加えて、学習時のエポック数を増やしてより学習させます。エポック数は100としました。
AtomS3でフラッシュ暗算する

ボタンを押し込むと予測値を合計する機能を追加してフラッシュ暗算をしました。
1 → 4 → 8 → 2 → 9 (合計:24)
見事フラッシュ暗算に成功しました。
録画し始めは手ブレによって数値予測がブレましたが、もともと認識しづらかった2や9といった数字文字をしっかりと認識しています。
おわりに
安価なマイコンや非力なマイコンといった制約がある中でもAIを組込んで、フルに活用することができました。 このように、株式会社Beeにはデバイスに応じてAIを組込む技術力があります。 今後も様々なマイコンでAI研究開発をしていきたいと思います。